Аннотация
Команда профессора Хань Чжоу из Национального университета обороны технологий опубликовала подход с улучшенным знанием для глубокого обучения с подкреплением (DRL) для многоагентного преследования и уклонения на IROS 2025. Система захвата движения NOKOV предоставила данные о положении и скорости нескольких дронов Crazyflie для поддержки проверки предложенного алгоритма.
Статья под названием «Возникающие кооперативные стратегии для преследования-уклонения в загроможденных средах: подход с улучшенным знанием для многоагентного глубокого обучения с подкреплением» на IROS 2025 предлагает метод DRL с улучшенным знанием для кооперативного преследования-уклонения в сложных условиях и проверяет его эффективность и превосходство через обширные численные симуляции и реальные эксперименты. Оптическая система захвата движения NOKOV предоставила высокоточные данные о положении и скорости дронов Crazyflie в реальных экспериментах, что позволило провести верификацию предложенного алгоритма.
Фон
Для повышения автономности и адаптивности многоагентных систем в задачах кооперативного преследования модельно-свободное глубокое обучение с подкреплением (DRL) появилось как перспективная альтернатива. Однако большинство существующих подходов на основе DRL до сих пор полагаются на индивидуальные награды и сталкиваются с трудностями в сложных сценариях.
Вклад
Для стимулирования кооперативного поведения между воспринимающими ограниченно преследователями в загроможденной среде эта статья предлагает алгоритм двойного задержанного градиента детерминированной политики (KE-MATD3) на основе командной награды с усиленным знанием. Главные вклады можно резюмировать следующим образом:
1. Предложен подход MADRL на основе командной награды для кооперативного многоагентного преследования в загроможденных средах, где задача моделируется как децентрализованный частично наблюдаемый процесс принятия решений Маркова.
2. Введенный механизм с усиленным знанием (KE) использует идеи из усовершенствованного метода искусственного потенциального поля (IAPF), тем самым способствуя обучению сложных командных наград.
3. Возникновение кооперативного поведения среди преследователей проверено как в симуляциях, так и в физических экспериментах.
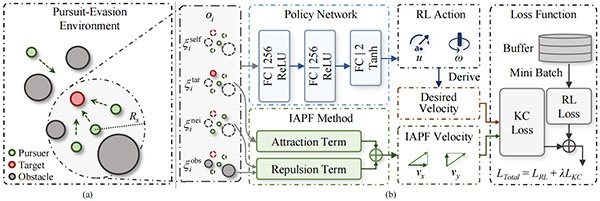
Системная структура для задач кооперативного преследования
(a) Многоагентная среда преследования-уклонения. (b) Предложенный алгоритм KE-MATD3.
Численные симуляционные эксперименты
В численных симуляциях предложенный алгоритм KE-MATD3 сравнивался с несколькими базовыми алгоритмами, включая MATD3, MADDPG, MADDQN и их варианты.
Результаты показывают, что благодаря внедрению механизма с усиленным знанием, KE-MATD3 значительно улучшает как эффективность обучения, так и конечную производительность, достигая наибольшей вероятности успешного захвата и наименьшего уровня столкновений.
При различной плотности препятствий KE-MATD3 постоянно демонстрировал высочайшую производительность, показывая сильную способность к обобщению. Это указывает на то, что предложенный подход может эффективно стимулировать кооперативное поведение в загроможденных средах и достигать эффективного захвата целей.
Реальные эксперименты
Экспериментальная установка состояла из арены размером 6.4 × 11 × 2 м, включающей пять дронов Crazyflie 2.1, систему захвата движения NOKOV, двадцать цилиндрических препятствий (радиус: 20 см, высота: 1 м) и бортовой компьютер.
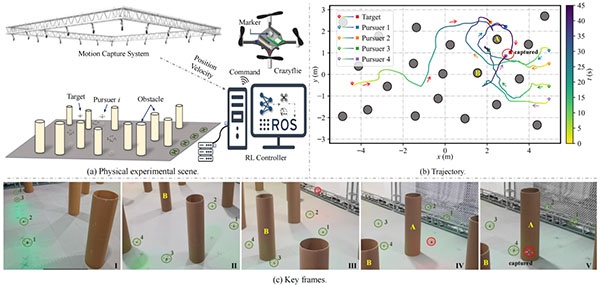
Результаты реальных экспериментов
Система захвата движения NOKOV отслеживала дроны Crazyflie с высокой точностью и предоставляла данные о текущем положении и скорости в реальном времени, которые передавались на бортовой компьютер через ROS.
Реальные эксперименты продемонстрировали, что предложенный метод безопасно и эффективно завершил задачу захвата, обеспечивая возникновение кооперативного поведения среди преследователей.
Результаты реальных экспериментов - видео
Система захвата движения NOKOV предоставила точные данные о положении и скорости нескольких дронов Crazyflie, поддерживая верификацию предложенного алгоритма.
Авторы
Ихао Сун — аспирант, Колледж интеллектуальных наук и технологий, Национальный университет обороны технологий. Исследовательские интересы: распределенное принятие решений для роев беспилотников.
Чжао Янь — Доцент-исследователь, Колледж автоматизации, Нанкинский университет аэронавтики и астронавтики. Исследовательские интересы: глубокое обучение, многоагентное обучение с подкреплением, кооперативное управление роями БПЛА и интеллектуальное принятие решений.
Хань Чжоу — Доцент, Колледж интеллектуальных наук и технологий, Национальный университет обороны технологий. Исследовательские интересы: кооперативное управление беспилотными системами.
Сяоцзя Сян — Профессор, Колледж интеллектуальных наук и технологий, Национальный университет обороны технологий, научный руководитель докторантуры. Исследовательские интересы: технологии беспилотных систем.
Цзе Цзян — Академик Китайской академии наук, Китайская академия технологии запуска ракет, научный руководитель докторантуры. Исследовательские интересы: навигация, управление и общее проектирование ракет-носителей.